







What are tokens?
Tokens can be thought of as pieces of words. Before the API processes the request, the input is broken down into tokens. These tokens are not cut up exactly where the words start or end - tokens can include trailing spaces and even sub-words. Here are some helpful rules of thumb for understanding tokens in terms of lengths:
To get additional context on how tokens stack up, consider this:
How words are split into tokens is also language-dependent. For example ‘Cómo estás’ (‘How are you’ in Spanish) contains 5 tokens (for 10 chars). The higher token-to-char ratio can make it more expensive to implement the API for languages other than English.
To further explore tokenization, you can use our interactive Tokenizer tool, which allows you to calculate the number of tokens and see how text is broken into tokens. Please note that the exact tokenization process varies between models. Newer models like GPT-3.5 and GPT-4 use a different tokenizer than previous models, and will produce different tokens for the same input text.
Alternatively, if you'd like to tokenize text programmatically, use Tiktoken as a fast BPE tokenizer specifically used for OpenAI models.
Token Limits
Depending on the model used, requests can use up to 128,000 tokens shared between prompt and completion. Some models, like GPT-4 Turbo, have different limits on input and output tokens.
There are often creative ways to solve problems within the limit, e.g. condensing your prompt, breaking the text into smaller pieces, etc.
Token Pricing
The API offers multiple model types at different price points. Requests to different models are priced differently. You can find details on token pricing here.
Exploring tokens
The API treats words according to their context in the corpus data. Models take the prompt, convert the input into a list of tokens, processes the prompt, and convert the predicted tokens back to the words we see in the response.
What might appear as two identical words to us may be generated into different tokens depending on how they are structured within the text. Consider how the API generates token values for the word ‘red’ based on its context within the text:
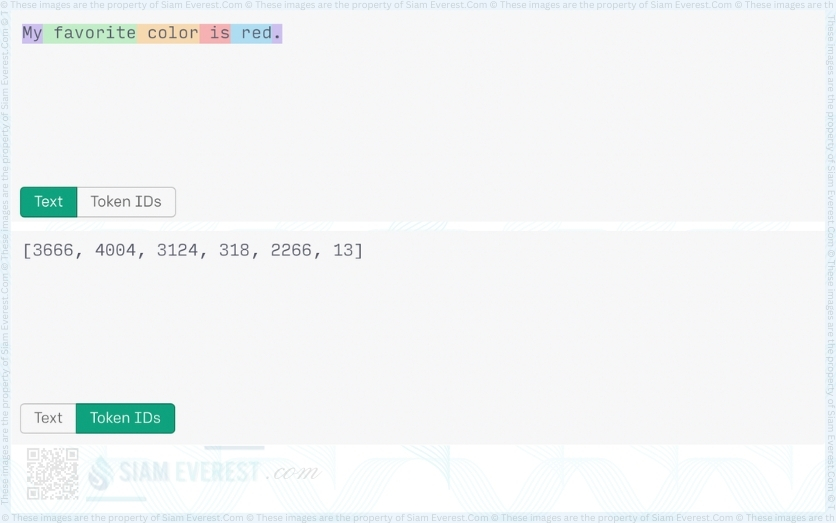
In the first example above the token “2266” for ‘ red’ includes a trailing space (Note, these are example token ID's for demonstration purposes).
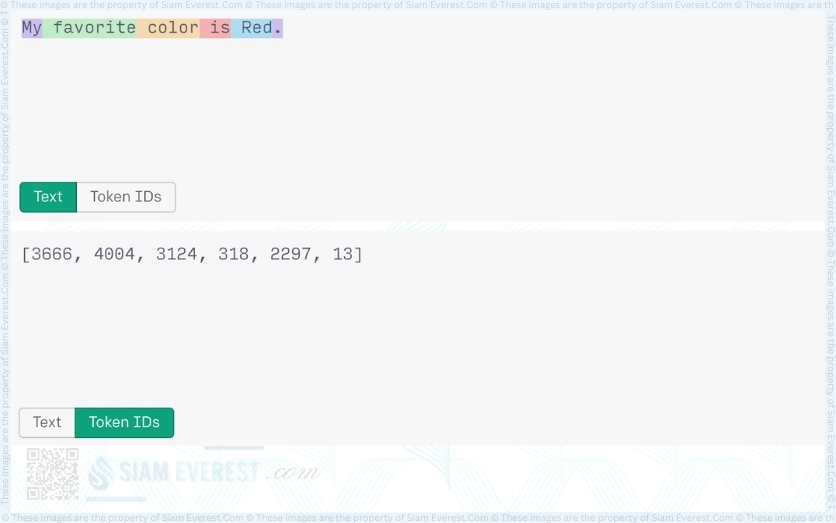
The token “2296” for ‘ Red’ (with a leading space and starting with a capital letter) is different from the token “2266” for ‘ red’ with a lowercase letter.
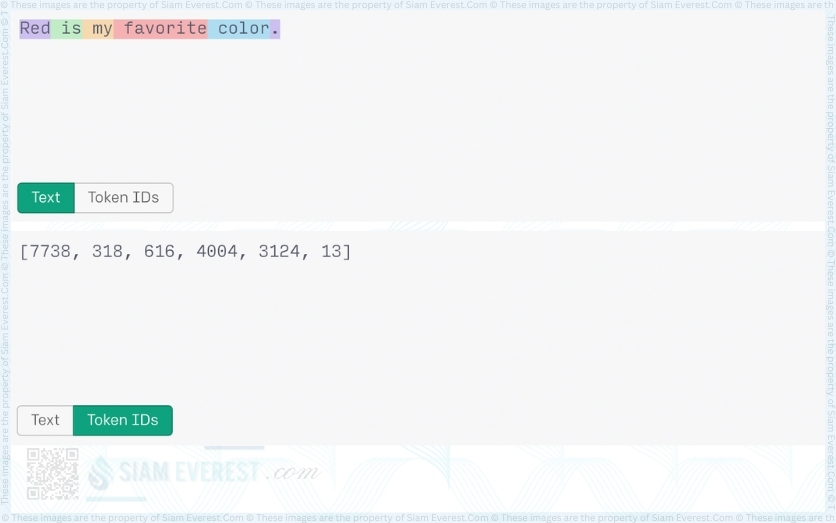
When ‘Red’ is used in the beginning of a sentence, the generated token does not include a leading space. The token “7738” is different from the previous two examples of the word.
Observations:
The more probable/frequent a token is, the lower the token number assigned to it: